FLUX.1 Kontext Dev について
FLUX.1 Kontext は、Black Forest Labs が開発した画期的なマルチモーダル画像編集モデルであり、テキストと画像を同時に入力可能で、画像の文脈を知的に理解し、高精度な編集を実行します。その開発版(Dev)は、120億パラメータを持つオープンソースの拡散トランスフォーマーモデルで、優れた文脈理解能力およびキャラクターの一貫性維持能力を備えています。そのため、複数回にわたる反復編集後でも、人物の特徴や構図レイアウトなどの重要な要素を安定して保持できます。 FLUX.1 Kontext シリーズ全体と同様のコア機能を提供します:- キャラクターの一貫性:複数のシーンや環境においても、画像内の参照キャラクターやオブジェクトといった固有の要素を維持します。
- 局所編集:画像内の特定要素に対して的確な変更を加え、他の部分には一切影響を与えません。
- スタイル参照:テキストプロンプトに基づき、参照画像の独自スタイルを保持したまま、新しいシーンを生成します。
- インタラクティブな速度:画像生成および編集における遅延が極めて小さいです。
バージョン情報
- [FLUX.1 Kontext [pro] — 商用版。高速な反復編集に特化
- FLUX.1 Kontext [max] — 実験版。プロンプトへの適合性がさらに強化されています
- FLUX.1 Kontext [dev] — オープンソース版(本チュートリアルで使用)。12B(120億)パラメータ。主に研究用途向け
モデルのダウンロード
本ガイドのワークフローを正常に実行するには、まず以下のモデルファイルをダウンロードする必要があります。また、対応するワークフローから直接モデルのダウンロードリンクを取得することも可能です(各ワークフローには既にモデルファイルのダウンロード情報が含まれています)。 Diffusion Model(拡散モデル) VAE Text Encoder(テキストエンコーダー) モデルの保存先Flux.1 Kontext Dev ワークフロー
Comfy Cloud で実行
このワークフローでは、編集対象の画像を読み込むためにLoad Image(from output) ノードを採用しており、編集後の画像を容易に取得・再利用できるため、複数回の反復編集がよりスムーズに行えます。
1. ワークフローおよび入力画像のダウンロード
以下のファイルをダウンロードし、ComfyUI にドラッグ&ドロップすることで、対応するワークフローを読み込めます。 入力画像
入力画像

2. ワークフローをステップごとに実行
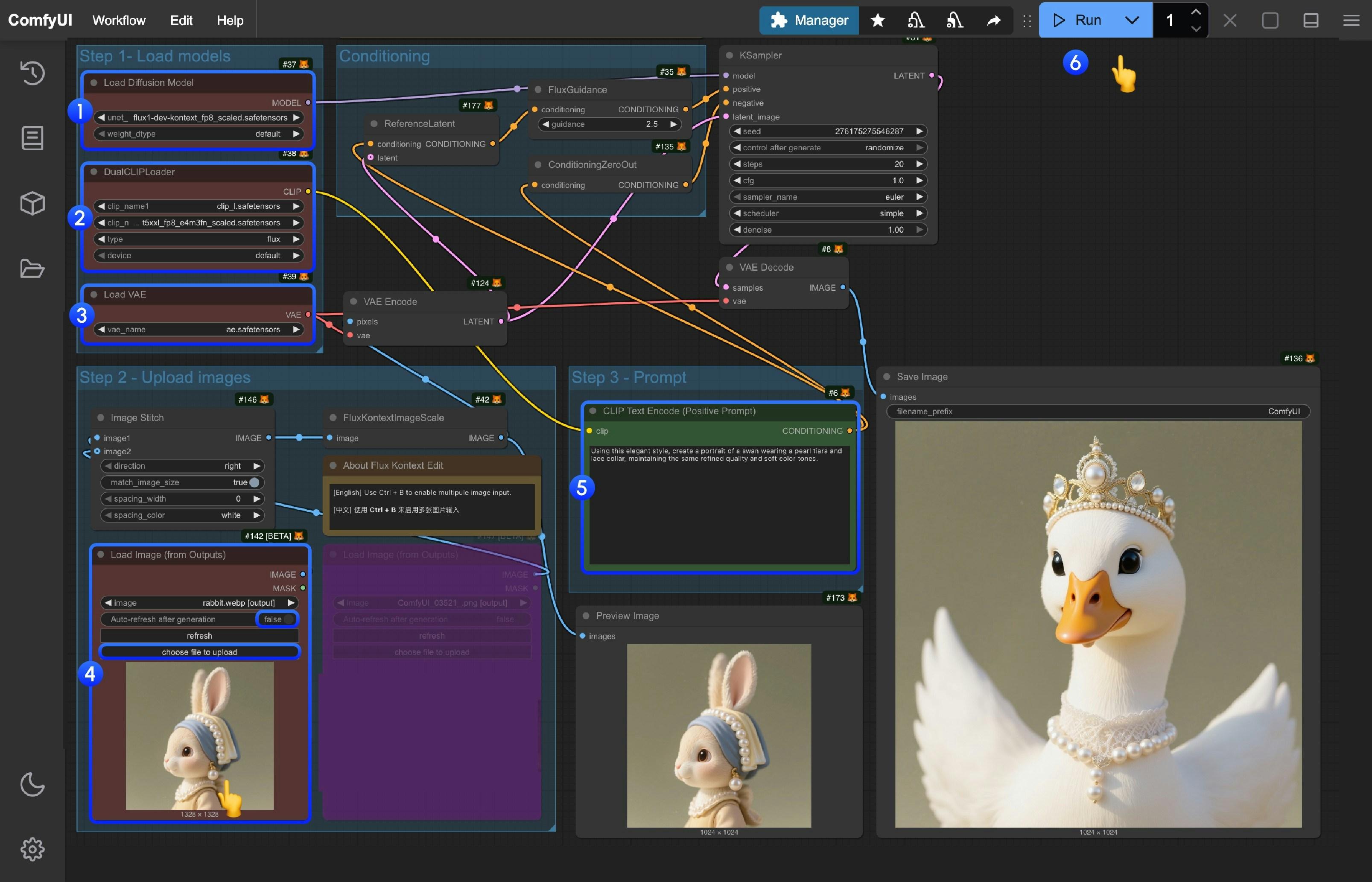
画像中の番号を参考に、ワークフローの実行を進めてください:
Load Diffusion Modelノードで、flux1-dev-kontext_fp8_scaled.safetensorsモデルを読み込みます。DualCLIP Loadノードで、clip_l.safetensorsおよびt5xxl_fp16.safetensorsまたはt5xxl_fp8_e4m3fn_scaled.safetensorsが正しく読み込まれていることを確認します。Load VAEノードで、ae.safetensorsモデルが読み込まれていることを確認します。Load Image(from output)ノードで、提供された入力画像を読み込みます。CLIP Text Encodeノードでプロンプトを編集します(英語のみ対応)。Queueボタンをクリックするか、ショートカットキーCtrl(Windows/Linux)/Cmd(macOS) + Enterを押してワークフローを実行します。
Flux Kontext プロンプト技法
1. 基本的な修正
- 簡潔かつ直接的:
"車の色を赤に変更" - スタイルを維持:
"絵画のスタイルをそのままに、昼間のシーンに変更"
2. スタイル転送
原則:- スタイルを明確に命名:
"バウハウス美術スタイルに変換" - 特徴を記述:
"筆跡がはっきりと見える油彩画、厚塗りのペインテクスチャに変換" - 構図を保持:
"オリジナルの構図を維持したまま、バウハウススタイルに変更"
3. キャラクターの一貫性
フレームワーク:- 具体的な記述:
"黒いショートヘアの女性"(代名詞"彼女"の代わり) - 特徴を保持:
"同じ顔の特徴、ヘアスタイル、表情を維持" - ステップごとの修正:まず背景を変更し、その後で動作などを変更
4. テキスト編集
- 引用符を使用:
"'joy' を 'BFL' に置き換え" - フォーマットを維持:
"同じフォントスタイルを維持したままテキストを置き換え"
よくある問題と解決策
キャラクターの変化が大きすぎる
❌ 不適切:"人物をバイキングに変換"
✅ 適切:"顔の特徴を維持したまま、衣装をバイキング戦士風に変更"
構図上の位置が変わってしまう
❌ 不適切:"彼をビーチに配置"
✅ 適切:"人物の位置、サイズ、ポーズを完全に同一に保ったまま、背景をビーチに変更"
スタイル適用が不正確
❌ 不適切:"スケッチ風にする"
✅ 適切:"自然なグラファイトライン、クロスハッチング、紙の質感が見える鉛筆スケッチに変換"
核心原則
- 具体性と明確さ — 精密な記述を用い、曖昧な語句は避ける
- ステップごとの編集 — 複雑な修正は、複数の単純なステップに分割する
- 明示的な保持指定 — 変更しない部分を明確に指示する
- 動詞の選択 —
"transform"ではなく、"change"や"replace"を優先して使用する
最適な実践テンプレート
オブジェクトの修正:"[オブジェクト] を [新しい状態] に変更し、[保持すべき内容] は変更しない"
スタイル転送:"[特定のスタイル] に変換し、[構図/キャラクター/その他の要素] は変更しない"
背景の置き換え:"背景を [新しい背景] に変更し、被写体の位置とポーズは完全に同一に保つ"
テキスト編集:"'[元のテキスト]' を '[新しいテキスト]' に置き換え、同じフォントスタイルを維持"
覚えておいてください: 指示はより具体的であるほど効果的です。Kontext は詳細な指示を正確に理解し、一貫性を維持するのに優れています。