FLUX.1-dev アーキテクチャを基盤とし、分離学習(disentangled learning)およびスタイル報酬学習(SRL:Style Reward Learning)により、スタイルの類似性と主体の一貫性の両方を実現しています。 USO は以下の3つの主要なアプローチをサポートします:
- 主体駆動型:主体を新しいシーンに配置しつつ、そのアイデンティティの一貫性を維持
- スタイル駆動型:参照画像に基づいて、新しいコンテンツに芸術的スタイルを適用
- 組み合わせ型:主体参照画像とスタイル参照画像を同時に使用
ByteDance USO ComfyUI ネイティブワークフロー
1. ワークフローと入力
以下の画像をダウンロードし、ComfyUI にドラッグ&ドロップして、対応するワークフローを読み込みます。
JSON ワークフローをダウンロード
Comfy Cloud で実行
以下の画像を入力画像として使用します。
2. モデルのダウンロードリンク
checkpoints loras model_patches clip_visions 上記すべてのモデルをダウンロードし、以下のディレクトリ構造に配置してください:3. ワークフローの操作手順
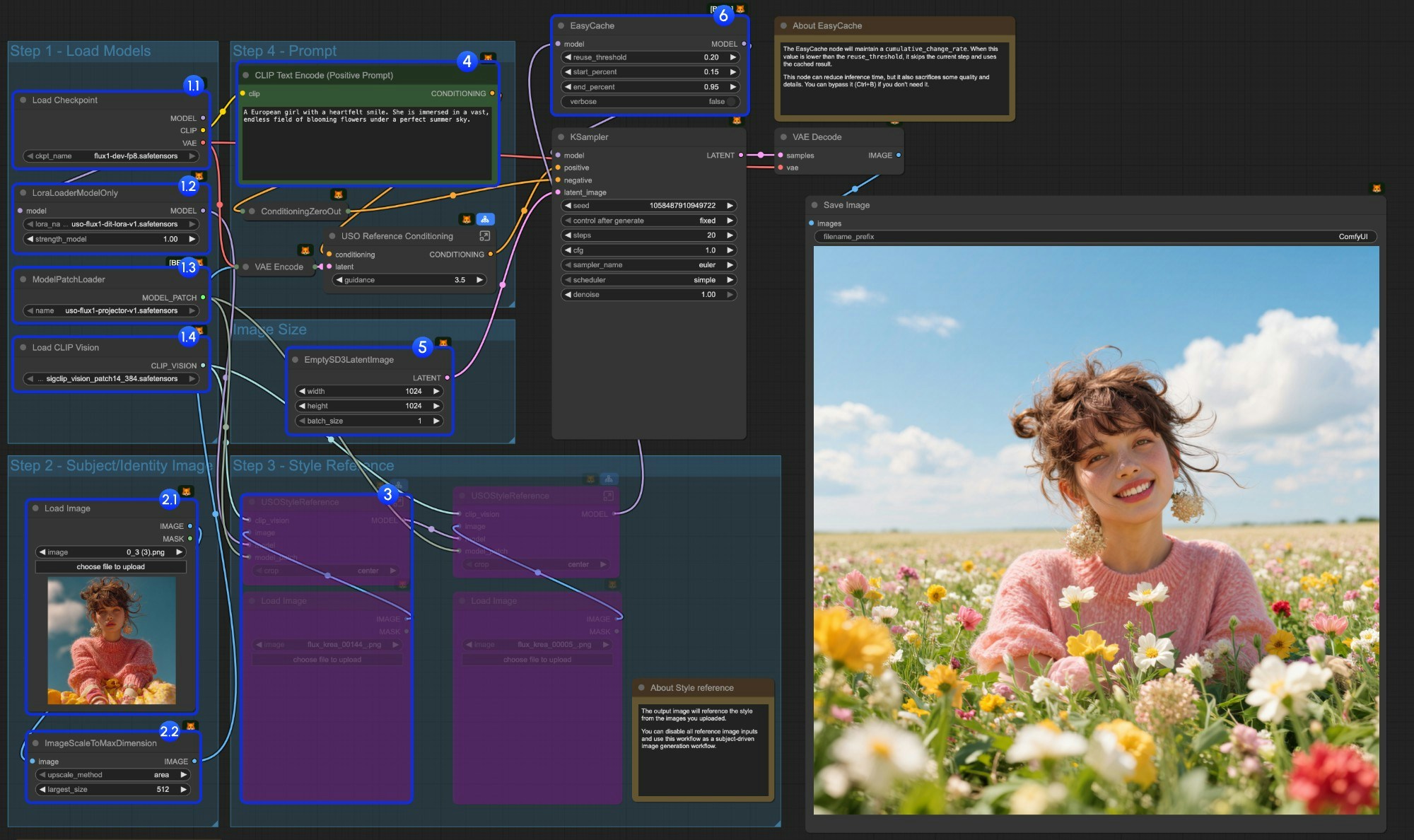
- モデルの読み込み:
- 1.1
Load Checkpointノードにflux1-dev-fp8.safetensorsが正しく読み込まれていることを確認 - 1.2
LoraLoaderModelOnlyノードにdit_lora.safetensorsが正しく読み込まれていることを確認 - 1.3
ModelPatchLoaderノードにprojector.safetensorsが正しく読み込まれていることを確認 - 1.4
Load CLIP Visionノードにsigclip_vision_patch14_384.safetensorsが正しく読み込まれていることを確認
- 1.1
- コンテンツ参照(主体参照):
- 2.1
Uploadをクリックして、提供済みの入力画像をアップロード - 2.2
ImageScaleToMaxDimensionノードが入力画像をコンテンツ参照用にスケーリングします。512px ではキャラクターの特徴をより多く保持できますが、入力としてキャラクターの顔のみを使用する場合、出力画像でキャラクターが画面を過剰に占めてしまう(または品質が低下する)問題が生じることがあります。1024px に設定すると、より良好な結果が得られます。
- 2.1
- この例では、
content reference(コンテンツ参照)の画像入力のみを使用しています。style reference(スタイル参照)の画像入力を使用したい場合は、マーカー付きノードグループをCtrl+Bでバイパスできます。 - プロンプトを自由に記述するか、デフォルトのまま使用
- 必要に応じて出力画像サイズを設定
EasyCacheノードは推論速度の向上を目的としていますが、画質およびディテールの一部を犠牲にします。不要な場合はCtrl+Bでバイパス可能です。Runボタンをクリックするか、ショートカットCtrl(Cmd) + Enterを使用してワークフローを実行
4. 補足情報
- スタイル参照のみのワークフロー:
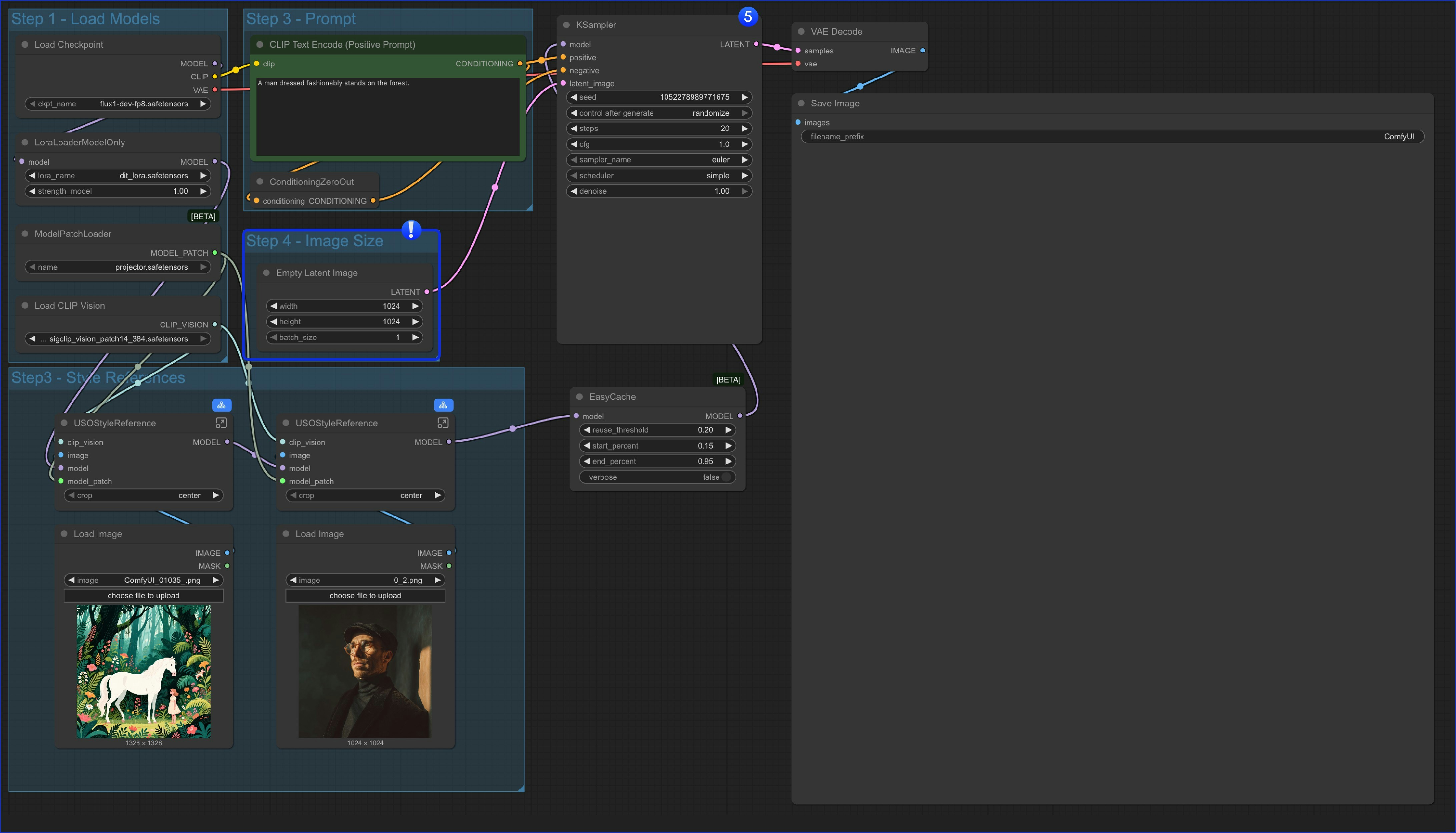
唯一の違いは、
content reference ノードを Empty Latent Image ノードに置き換え、必要な画像サイズを生成することです。
- また、
Style Referenceグループ全体をCtrl+Bでバイパスすることで、このワークフローをテキストから画像を生成する(text-to-image)ワークフローとしても利用可能です。つまり、本ワークフローには以下の4種類のバリエーションがあります:
- コンテンツ(主体)参照のみを使用
- スタイル参照のみを使用
- コンテンツ参照とスタイル参照を併用
- テキストから画像を生成する(text-to-image)ワークフローとして使用