What are Partner Nodes?
Partner Nodes are a set of special nodes that connect to external API services, allowing you to use closed-source or third-party hosted AI models directly in your ComfyUI workflows. These nodes are designed to seamlessly integrate the capabilities of external models while maintaining the open-source nature of ComfyUI’s core.Prerequisites for Using Partner Nodes
To use Partner Nodes, the following requirements must be met:1. ComfyUI Version Requirements
Please update your ComfyUI to the latest version, as we may add more API support in the future, and corresponding nodes will be updated, so please keep your ComfyUI up to date.2. Account and Credits Requirements
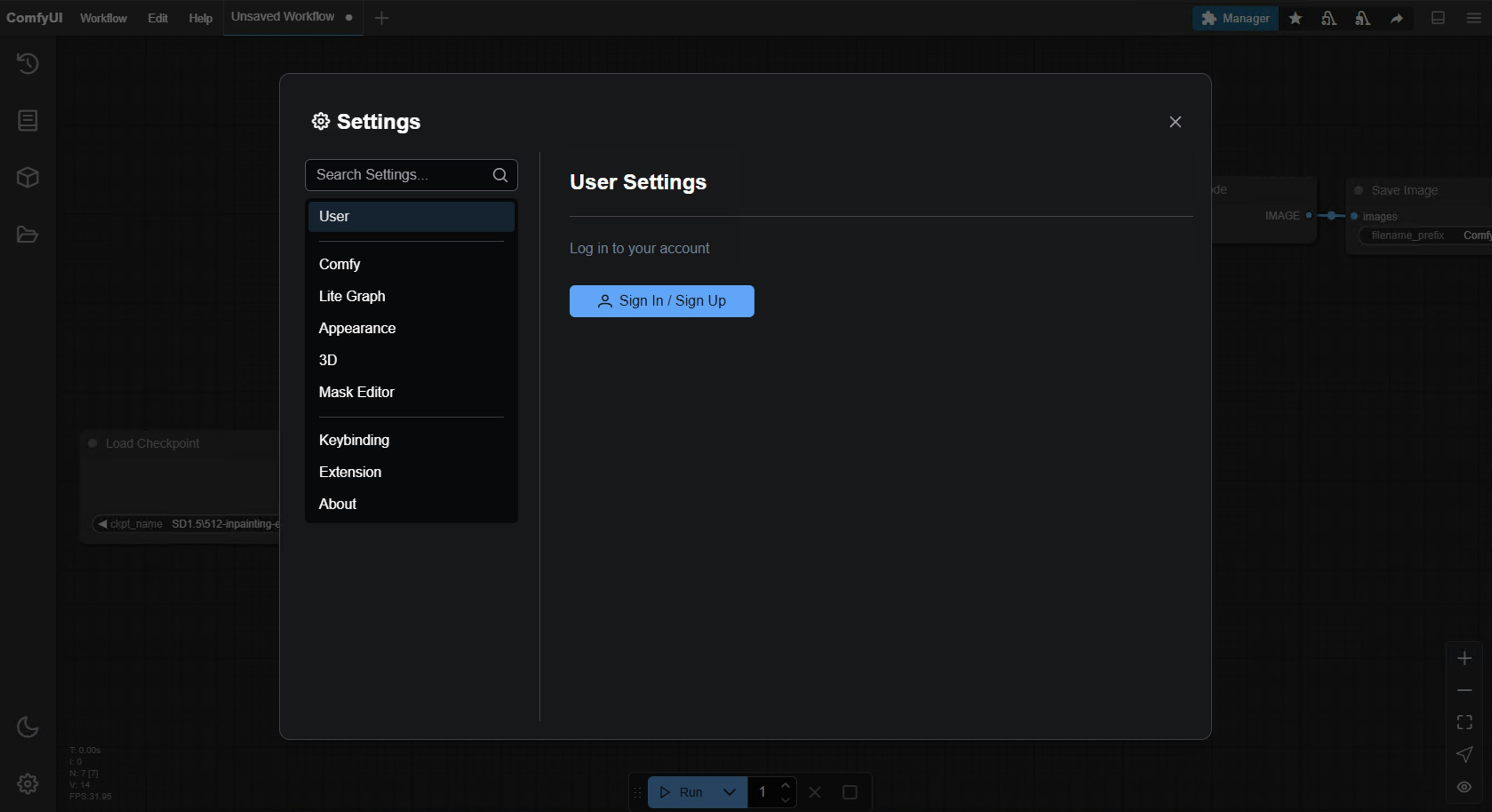
You need to be logged into your ComfyUI with a Comfy account and have a credit balance of credits greater than 0. Log in viaSettings -> User:
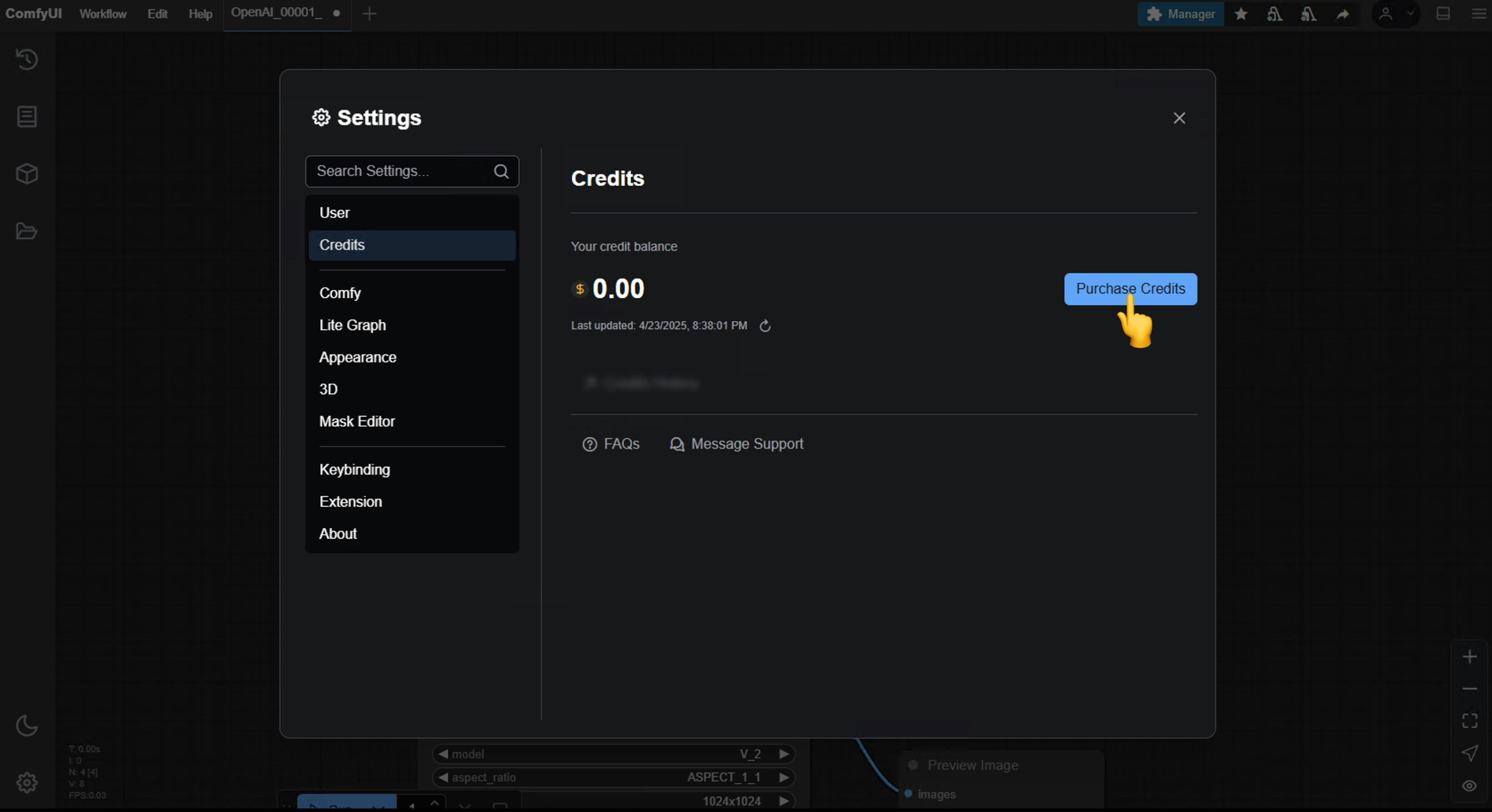
Settings -> Credits to purchase credits
- Comfy account: Find the
Usersection in the settings menu to log in. - Credits: After logging in, the settings interface will show a credits menu where you can purchase credits. We use a prepaid system, so there will be no unexpected charges.
3. Network Environment Requirements
API access requires that your current requests are based on a secure network environment. The current requirements for API access are as follows:- The local network only allows access from
127.0.0.1orlocalhost, and you can directly use the login function. - If you are accessing from a local area network or a website that is not on the whitelist, please log in with an API Key. Please refer to Log in with an API Key.
- You should be able to access our API service normally (in some regions, you may need to use a proxy service).
- Access should be carried out in an
httpsenvironment to ensure the security of the requests.
Accessing in an insecure context poses significant risks, which may result in the following consequences:
- Authentication may be stolen, leading to the leakage of your account information.
- Your account may be maliciously used, resulting in financial losses.
4. Using the Corresponding Nodes
Add to Workflow: Add the Partner Node to your workflow just like you would with other nodes. Run: Set the parameters and then run the workflow.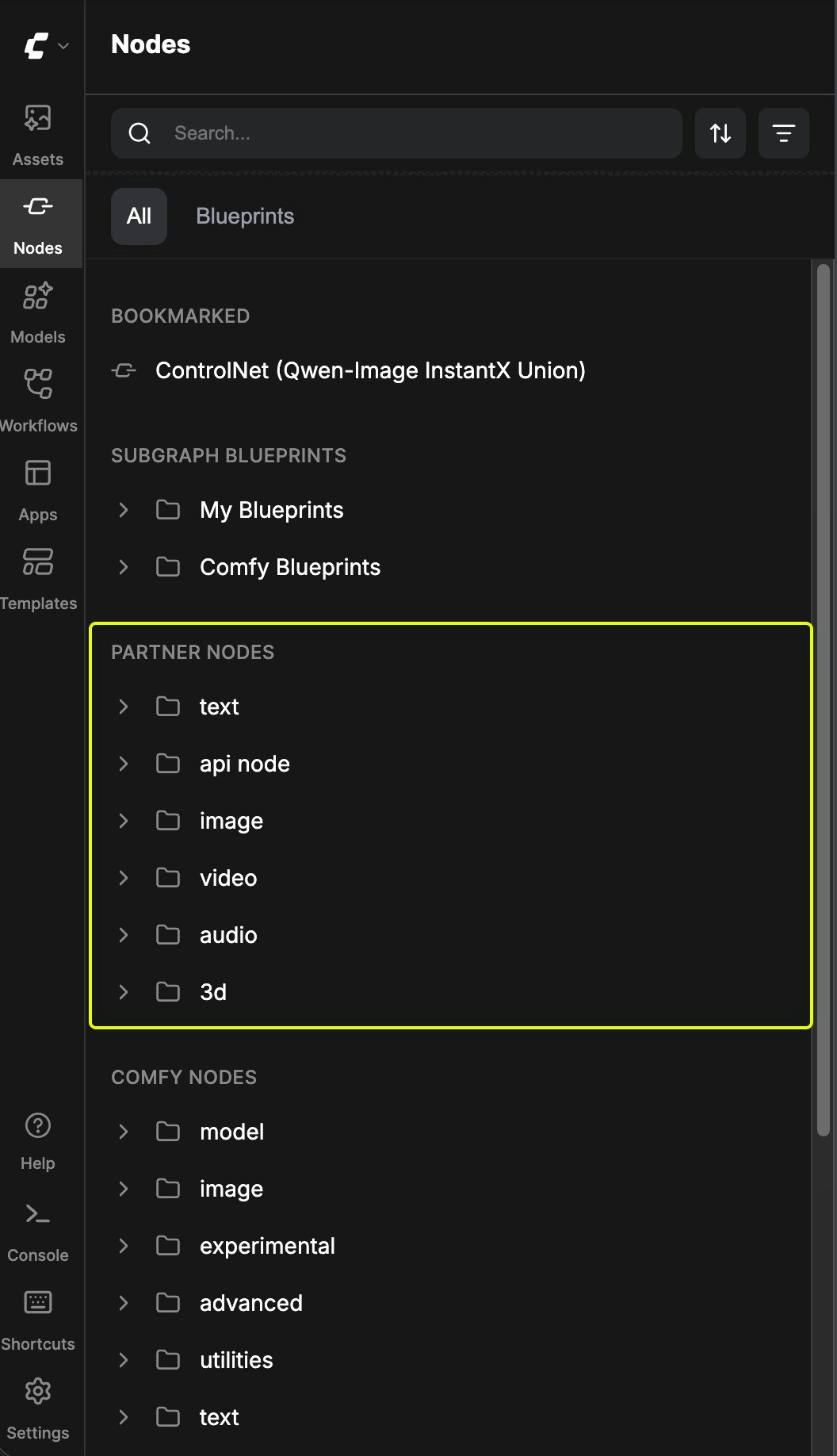
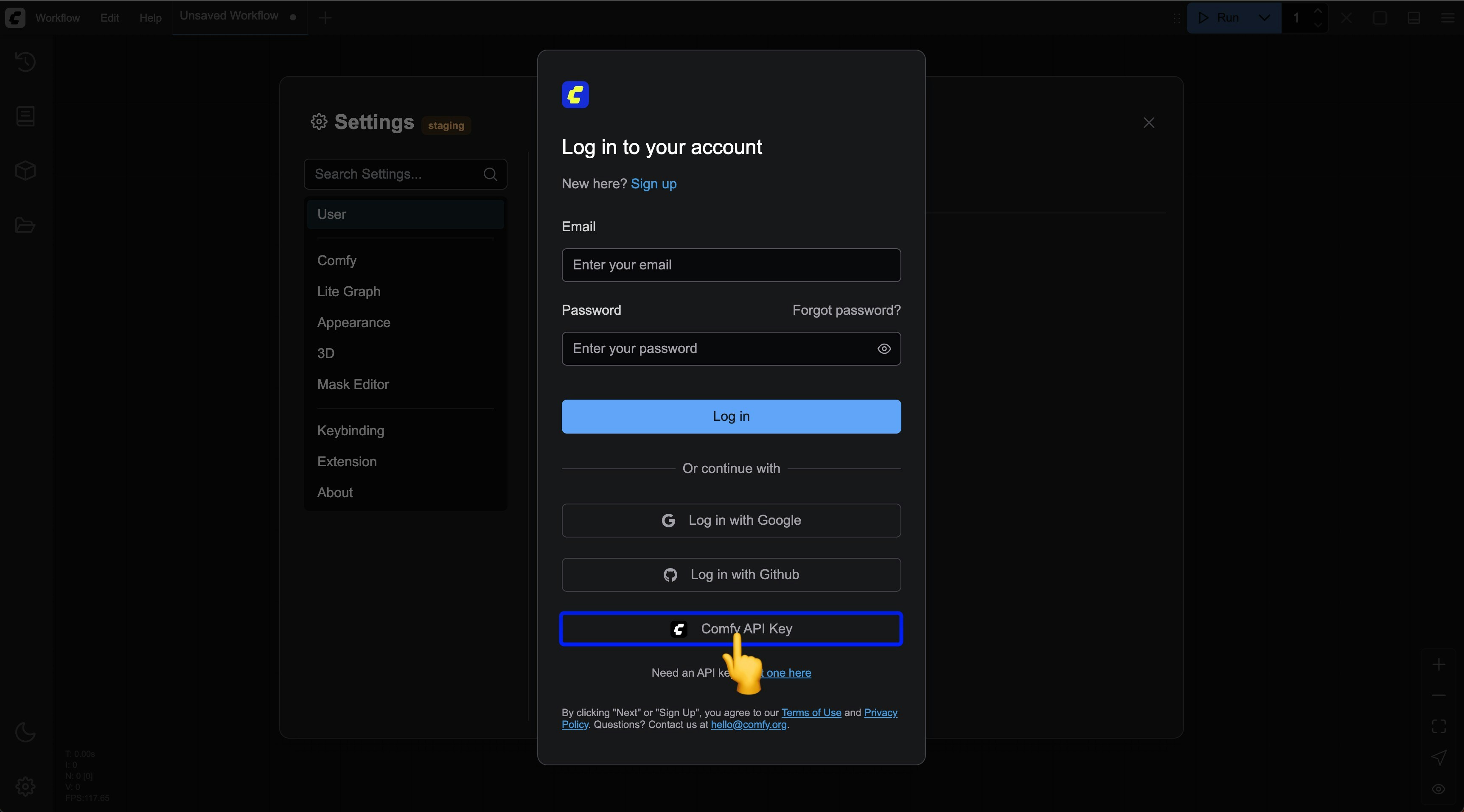
Log in with ComfyUI Account API Key on non-whitelisted websites
Currently, we have set up a whitelist to restrict the websites where you can log in to your ComfyUI account. If you need to log in to your ComfyUI account on some non-whitelisted websites, please refer to the account management section to learn how to log in using an API Key. In this case, the corresponding website does not need to be on our whitelist.Account Management
Learn how to log in with ComfyUI Account API Key
Use ComfyUI Account API Key Integration to call paid model Partner nodes
Currently, we support accessing our services through ComfyUI API Key Integration to call paid model Partner nodes. Please refer to the API Key Integration section to learn how to use API Key Integration to call paid model Partner nodes.Important: The API key discussed here is your ComfyUI Account API Key (used for accessing paid Partner nodes in workflows). This is NOT the same as the Registry Publishing API Key used by developers to publish custom nodes to the registry. If you’re looking to publish custom nodes, see Publishing Nodes.
API Key Integration
Please refer to the API Key Integration section to learn how to use API Key Integration to call paid model Partner nodes
Advantages of Partner Nodes
Partner Nodes provide several important advantages for ComfyUI users:- Access to closed-source models: Use state-of-the-art AI models without having to deploy them yourself
- Seamless integration: Partner nodes are fully compatible with other ComfyUI nodes and can be combined to create complex workflows
- Simplified experience: No need to manage API keys or handle complex API requests
- Controlled costs: The prepaid system ensures you have complete control over your spending with no unexpected charges
Pricing
Partner Node Pricing
Please refer to the pricing page for the corresponding Partner pricing
About Open Source and Opt-in
It’s important to note that Partner Nodes are completely optional. ComfyUI will always remain fully open-source and free for local users. Partner nodes are designed as an “opt-in” feature, providing convenience for those who want access to external SOTA (state-of-the-art) models.How to disable partner nodes completely
You can add the--disable-api-nodes launch argument to disable all partner nodes in ComfyUI. This argument will also prevent the frontend from communicating with the internet.
For manual install:
run_xxx.bat file:
Use Cases
A powerful application of Partner Nodes is combining the output of external models with local nodes. For example:- Using GPT-Image-1 to generate a base image, then transforming it into video with a local
wannode - Combining externally generated images with local upscaling or style transfer nodes
- Creating hybrid workflows that leverage the advantages of both closed-source and open-source models
FAQs
Why can't I find the Partner Nodes?
Why can't I find the Partner Nodes?
Please update your ComfyUI to the latest version (the latest commit or the latest desktop version).
We may add more API support in the future, and the corresponding nodes will be updated, so please keep your ComfyUI up to date.
Why can't I use / log in to the Partner Nodes?
Why can't I use / log in to the Partner Nodes?
API access requires that your current request is based on a secure network environment. The current requirements for API access are as follows:
- The local network only allows access from
127.0.0.1orlocalhost, which may mean that you cannot use the Partner Nodes in a ComfyUI service started with the--listenparameter in a LAN environment. - Able to access our API service normally (a proxy service may be required in some regions).
- Your account does not have enough credits.
Why can't I use Partner Node even after logging in, or why does it keep asking me to log in while using?
Why can't I use Partner Node even after logging in, or why does it keep asking me to log in while using?
- Currently, only
127.0.0.1orlocalhostaccess is supported. - Ensure your account has enough credits.
Can Partner Nodes be used for free?
Can Partner Nodes be used for free?
Partner Nodes require credits for API calls to closed-source models, so they do not support free usage.
How to purchase credits?
How to purchase credits?
Please refer to the following documentation:
- Comfy Account: Find the
Usersection in the settings menu to log in. - Credits: After logging in, the settings interface will show the credits menu. You can purchase credits in
Settings→Credits. We use a prepaid system, so there will be no unexpected charges. - Complete the payment through Stripe.
- Check if the credits have been updated. If not, try restarting or refreshing the page.
Are unused credits refundable?
Are unused credits refundable?
Currently, we do not support refunds for credits.
If you believe there is an error resulting in unused balance due to technical issues, please contact support.
Can credits go negative?
Can credits go negative?
Credits are not intended to be used as a negative balance or credit line. However, due to race conditions where partner nodes don’t always report costs before execution, a single execution may consume more credits than your remaining balance and temporarily result in a negative balance after completion. When your balance is negative, you will not be able to run Partner Nodes until you top up and restore a positive balance. Please ensure you have enough credits before making API calls.
Where can I check usage and expenses?
Where can I check usage and expenses?
Please visit the Credits menu after logging in to check the corresponding credits.
Is it possible to use my own API Key?
Is it possible to use my own API Key?
Currently, the Partner Nodes are still in the testing phase and do not support this feature yet, but we have considered adding it.
Do credits expire?
Do credits expire?
Yes, the expiration depends on the type of credits:
- Monthly credits: Expire at the end of your billing period
- Top-up credits: Expire 1 year from the date of purchase
Can I use the same account on different devices?
Can I use the same account on different devices?
We do not limit the number of devices that can log in; you can use your account anywhere you want.
How can I request for my account or information to be deleted??
How can I request for my account or information to be deleted??
Email a request to support@comfy.org and we will delete your information
Is there content moderation for Partner Nodes?
Is there content moderation for Partner Nodes?
Partner Nodes send your inputs (prompts, images, and other content) to third-party providers for processing. These providers enforce their own content moderation policies. Please do not submit NSFW or other prohibited content to API nodes.