About OmniGen2
OmniGen2 is a powerful and efficient unified multimodal generation model with approximately 7B total parameters (3B text model + 4B image generation model). Unlike OmniGen v1, OmniGen2 adopts an innovative dual-path Transformer architecture with completely independent text autoregressive model and image diffusion model, achieving parameter decoupling and specialized optimization.Model Highlights
- Visual Understanding: Inherits the powerful image content interpretation and analysis capabilities of the Qwen-VL-2.5 foundation model
- Text-to-Image Generation: Creates high-fidelity and aesthetically pleasing images from text prompts
- Instruction-guided Image Editing: Performs complex, instruction-based image modifications, achieving state-of-the-art performance among open-source models
- Contextual Generation: Versatile capabilities to process and flexibly combine diverse inputs (including people, reference objects, and scenes), producing novel and coherent visual outputs
Technical Features
- Dual-path Architecture: Based on Qwen 2.5 VL (3B) text encoder + independent diffusion Transformer (4B)
- Omni-RoPE Position Encoding: Supports multi-image spatial positioning and identity distinction
- Parameter Decoupling Design: Avoids negative impact of text generation on image quality
- Support for complex text understanding and image understanding
- Controllable image generation and editing
- Excellent detail preservation capabilities
- Unified architecture supporting multiple image generation tasks
- Text generation capability: Can generate clear text content within images
OmniGen2 Model Download
Since this article involves different workflows, the corresponding model files and installation locations are as follows. The download information for model files is also included in the corresponding workflows: Diffusion Models VAE Text Encoders File save location:ComfyUI OmniGen2 Text-to-Image Workflow
1. Download Workflow File
Run on Comfy Cloud

2. Complete Workflow Step by Step
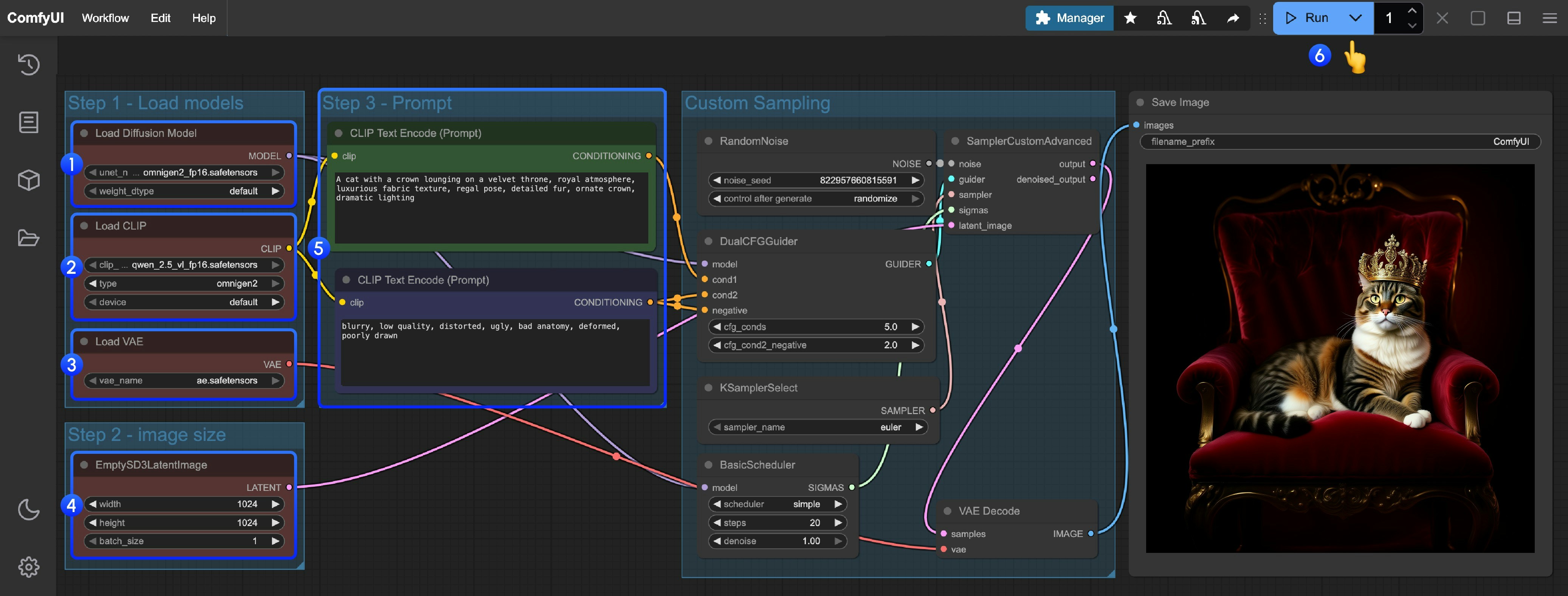
- Load Main Model: Ensure the
Load Diffusion Modelnode loadsomnigen2_fp16.safetensors - Load Text Encoder: Ensure the
Load CLIPnode loadsqwen_2.5_vl_fp16.safetensors - Load VAE: Ensure the
Load VAEnode loadsae.safetensors - Set Image Dimensions: Set the generated image dimensions in the
EmptySD3LatentImagenode (recommended 1024x1024) - Input Prompts:
- Input positive prompts in the first
CLipTextEncodenode (content you want to appear in the image) - Input negative prompts in the second
CLipTextEncodenode (content you don’t want to appear in the image)
- Input positive prompts in the first
- Start Generation: Click the
Queue Promptbutton, or use the shortcutCtrl(cmd) + Enterto execute text-to-image generation - View Results: After generation is complete, the corresponding images will be automatically saved to the
ComfyUI/output/directory, and you can also preview them in theSaveImagenode
ComfyUI OmniGen2 Image Editing Workflow
OmniGen2 has rich image editing capabilities and supports adding text to images1. Download Workflow File
Run on Comfy Cloud
 Download the image below, which we will use as the input image.
Download the image below, which we will use as the input image.

2. Complete Workflow Step by Step
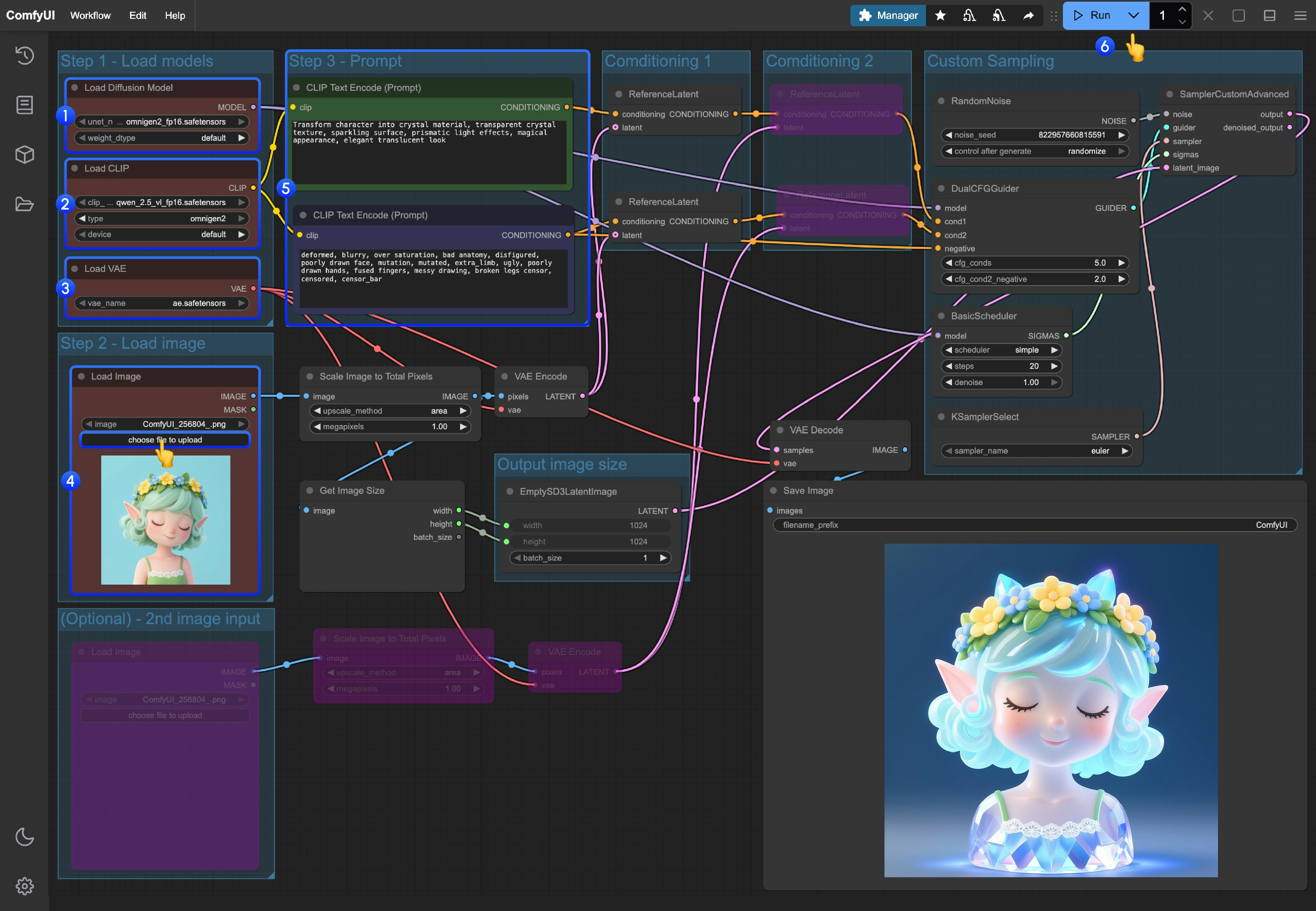
- Load Main Model: Ensure the
Load Diffusion Modelnode loadsomnigen2_fp16.safetensors - Load Text Encoder: Ensure the
Load CLIPnode loadsqwen_2.5_vl_fp16.safetensors - Load VAE: Ensure the
Load VAEnode loadsae.safetensors - Upload Image: Upload the provided image in the
Load Imagenode - Input Prompts:
- Input positive prompts in the first
CLipTextEncodenode (content you want to appear in the image) - Input negative prompts in the second
CLipTextEncodenode (content you don’t want to appear in the image)
- Input positive prompts in the first
- Start Generation: Click the
Queue Promptbutton, or use the shortcutCtrl(cmd) + Enterto execute text-to-image generation - View Results: After generation is complete, the corresponding images will be automatically saved to the
ComfyUI/output/directory, and you can also preview them in theSaveImagenode
3. Additional Workflow Instructions
- If you want to enable the second image input, you can use the shortcut Ctrl + B to enable the corresponding node inputs for nodes that are in pink/purple state in the workflow
- If you want to customize dimensions, you can delete the
Get image sizenode linked to theEmptySD3LatentImagenode and input custom dimensions