주요 특징
- 통합 모션 제어: 객체, 국소 영역, 카메라 움직임 등 여러 가지 모션 유형에 대한 트래젝터리 제어를 지원합니다.
- 인터랙티브 트래젝터리 에디터: 사용자가 이미지 위에 자유롭게 모션 트래젝터리를 그려서 편집할 수 있는 시각적 도구입니다.
- Wan2.1 호환: 공식 Wan2.1 구현을 기반으로 하며, 환경과 모델 구조와 호환됩니다.
- 풍부한 시각화 도구: 입력 트래젝터리, 출력 비디오, 트래젝터리 오버레이의 시각화를 지원합니다.
WAN ATI 트래젝터리 제어 워크플로우 예시
1. 워크플로우 다운로드
아래 비디오를 다운로드한 후 ComfyUI로 드래그하여 해당 워크플로우를 로드하세요. 다음 이미지를 입력으로 사용하겠습니다:
2. 모델 다운로드
워크플로우에서 모델 파일을 성공적으로 다운로드하지 못했다면, 아래 링크를 이용해 수동으로 다운로드해 보세요. 디퓨전 모델 VAE 텍스트 인코더다음 모델 중 하나를 선택하세요: clip_vision 파일 저장 위치
3. 워크플로우를 단계별로 완료하세요
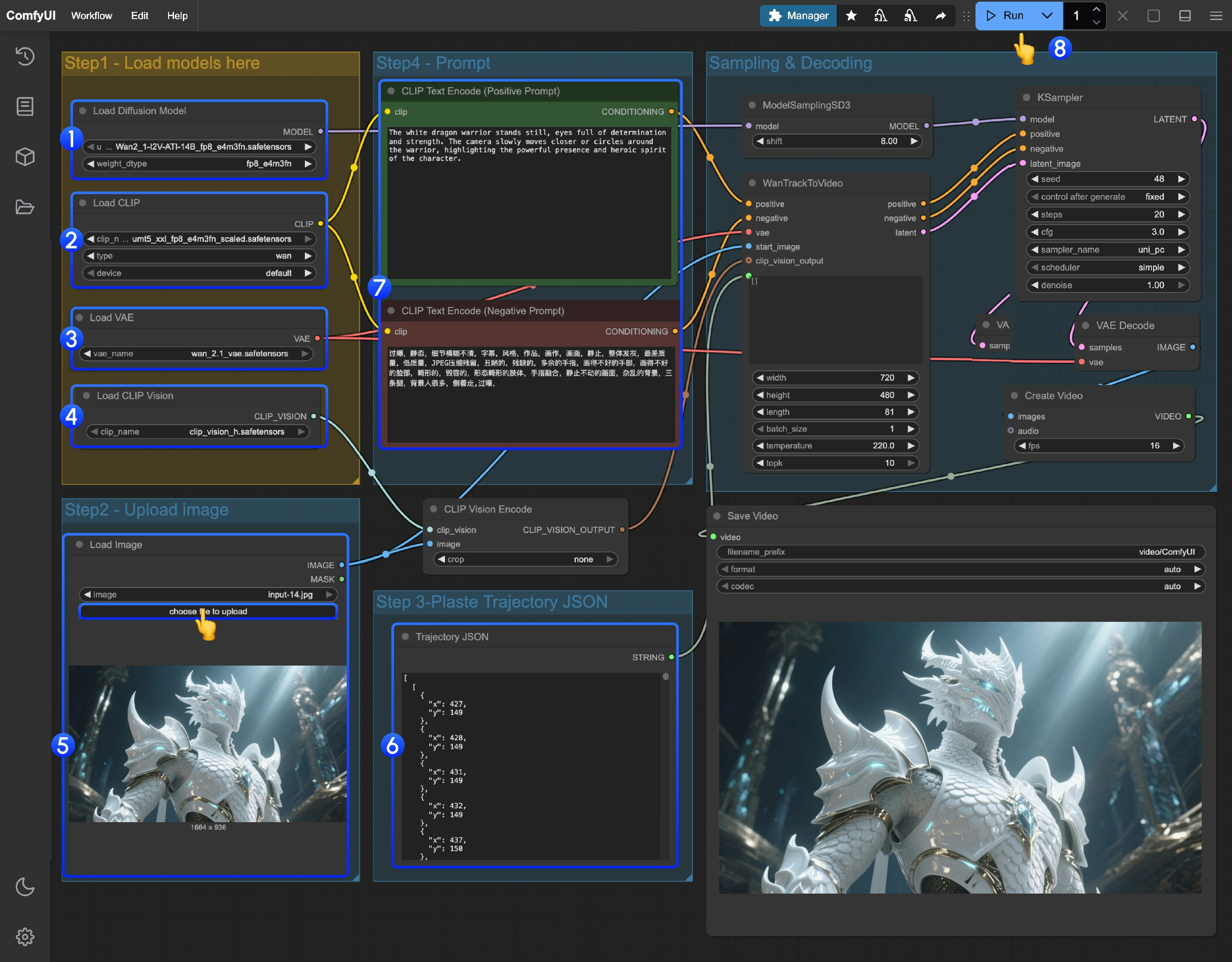
Load Diffusion Model노드가Wan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensors모델을 로드했는지 확인하세요.Load CLIP노드가umt5_xxl_fp8_e4m3fn_scaled.safetensors모델을 로드했는지 확인하세요.Load VAE노드가wan_2.1_vae.safetensors모델을 로드했는지 확인하세요.Load CLIP Vision노드가clip_vision_h.safetensors모델을 로드했는지 확인하세요.- 제공된 입력 이미지를
Load Image노드에 업로드하세요. - 트래젝터리 편집: 현재 ComfyUI에는 해당하는 트래젝터리 에디터가 없으므로, 다음 링크를 이용해 트래젝터리 편집을 완료할 수 있습니다.
- 프롬프트(긍정 및 부정)를 수정해야 한다면, 번호
5의CLIP Text Encoder노드에서 변경하세요. Run버튼을 클릭하거나 단축키Ctrl(cmd) + Enter를 사용해 비디오 생성을 실행하세요.