- Multi-modal Control: Supports multiple control conditions including Canny (line art), Depth, OpenPose (human pose), MLSD (geometric edges), and trajectory control
- High-Quality Video Generation: Based on the Wan2.2 architecture, outputs film-level quality videos
- Multi-language Support: Supports multi-language prompts including Chinese and English
- 🤗Wan2.2-Fun-A14B-Control
- Code repository: VideoX-Fun
ComfyOrg Wan2.2 Fun InP & Control Youtube Live Stream Replay
Wan2.2 Fun Control Video Generation Workflow Example
This workflow provides two versions:- A version using Wan2.2-Lightning 4-step LoRA from lightx2v: may cause some loss in video dynamics but offers faster speed
- A fp8_scaled version without acceleration LoRA
Since using the 4-step LoRA provides a better experience for first-time workflow users, but may cause some loss in video dynamics, we have enabled the accelerated LoRA version by default. If you want to enable the other workflow, select it and use Ctrl+B to activate.
1. Download Workflow and Materials
Download the video below or JSON file and drag it into ComfyUI to load the workflowDownload JSON Workflow
Please download the following images and videos as input materials.
We use a preprocessed video here.
2. Models
You can find the models below at Wan_2.2_ComfyUI_Repackaged Diffusion Model- wan2.2_fun_control_high_noise_14B_fp8_scaled.safetensors
- wan2.2_fun_control_low_noise_14B_fp8_scaled.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
3. Workflow Guide
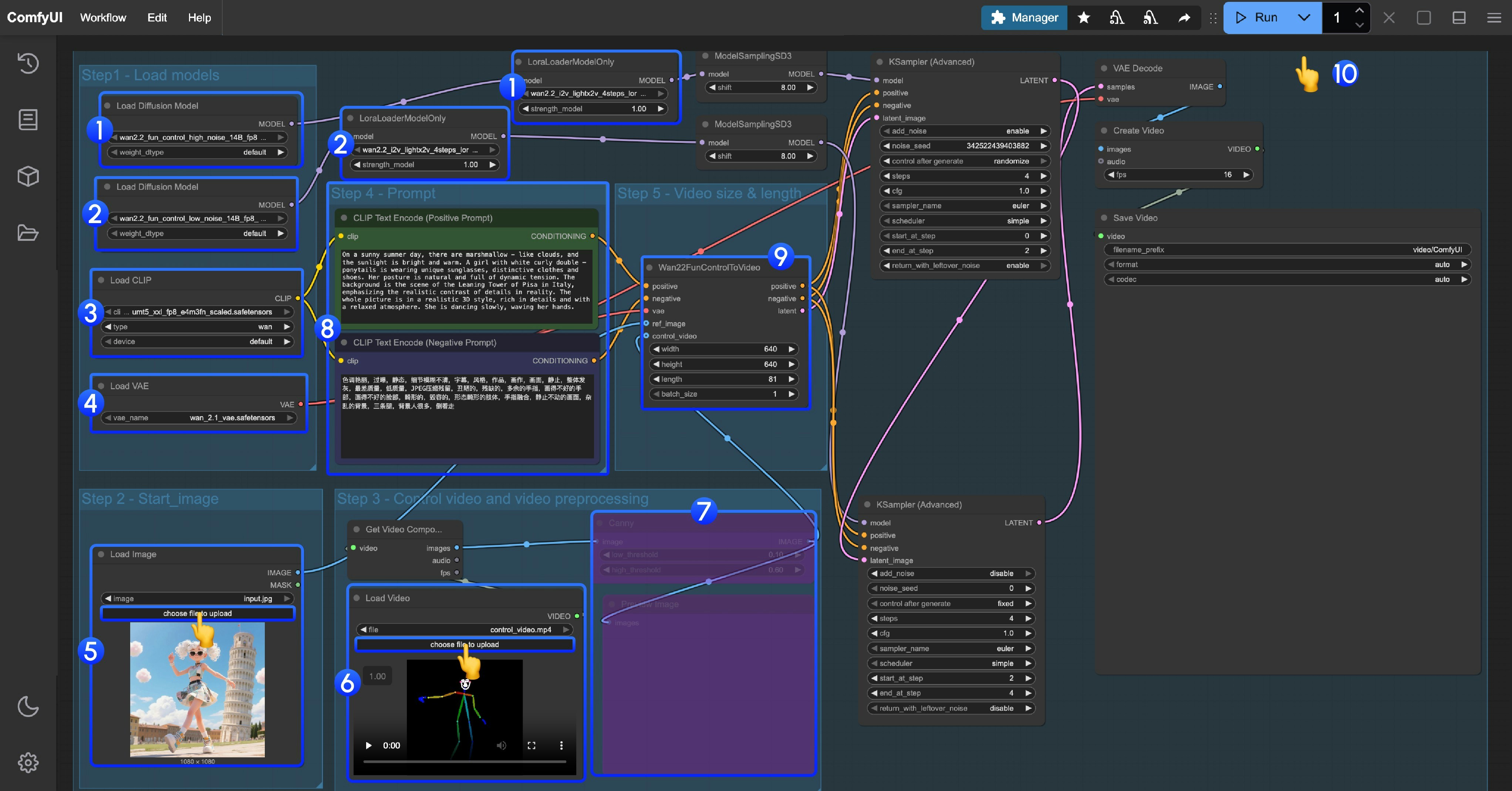
This workflow uses LoRA. Please ensure the corresponding Diffusion model and LoRA are matched - high noise and low noise models and LoRAs need to be used correspondingly.
- High noise model and LoRA loading
- Ensure the
Load Diffusion Modelnode loads thewan2.2_fun_control_high_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
LoraLoaderModelOnlynode loads thewan2.2_i2v_lightx2v_4steps_lora_v1_high_noise.safetensors
- Ensure the
- Low noise model and LoRA loading
- Ensure the
Load Diffusion Modelnode loads thewan2.2_fun_control_low_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
LoraLoaderModelOnlynode loads thewan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
- Ensure the
- Ensure the
Load CLIPnode loads theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode loads thewan_2.1_vae.safetensorsmodel - Upload the start frame in the
Load Imagenode - In the second
Load videonode, load the pose control video. The provided video has been preprocessed and can be used directly - Since we provide a preprocessed pose video, the corresponding video image preprocessing node needs to be disabled. You can select it and use
Ctrl + Bto disable it - Modify the Prompt - you can use both Chinese and English
- In
Wan22FunControlToVideo, modify the video dimensions. The default is set to 640×640 resolution to avoid excessive processing time for users with low VRAM - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation