- 14B (14 billion parameters)
- 1.3B (1.3 billion parameters) Covering multiple tasks including text-to-video (T2V) and image-to-video (I2V). The model not only outperforms existing open-source models in performance but more importantly, its lightweight version requires only 8GB of VRAM to run, significantly lowering the barrier to entry.
Wan2.1 ComfyUI Native Workflow Examples
Model Installation
All models mentioned in this guide can be found here. Below are the common models you’ll need for the examples in this guide, which you can download in advance: Choose one version from Text encoders to download: VAE CLIP Vision File storage locations:For diffusion models, we’ll use the fp16 precision models in this guide because we’ve found that they perform better than the bf16 versions. If you need other precision versions, please visit here to download them.
Wan2.1 Text-to-Video Workflow
Before starting the workflow, please download wan2.1_t2v_1.3B_fp16.safetensors and save it to theComfyUI/models/diffusion_models/ directory.
If you need other t2v precision versions, please visit here to download them.
1. Workflow File Download
Download the file below and drag it into ComfyUI to load the corresponding workflow:
2. Complete the Workflow Step by Step
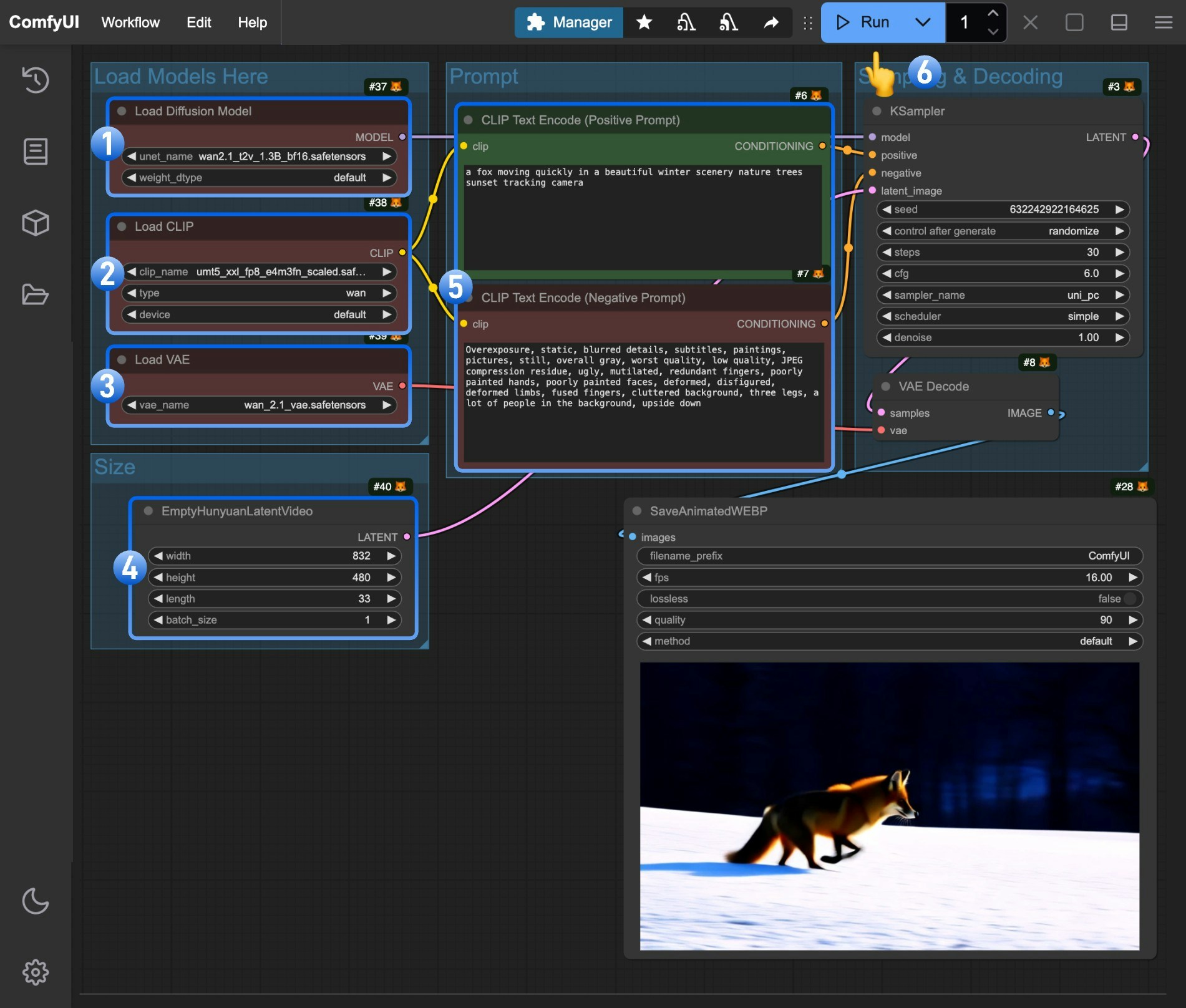
- Make sure the
Load Diffusion Modelnode has loaded thewan2.1_t2v_1.3B_fp16.safetensorsmodel - Make sure the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Make sure the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - (Optional) You can modify the video dimensions in the
EmptyHunyuanLatentVideonode if needed - (Optional) If you need to modify the prompts (positive and negative), make changes in the
CLIP Text Encodernode at number5 - Click the
Runbutton or use the shortcutCtrl(cmd) + Enterto execute the video generation
Wan2.1 Image-to-Video Workflow
Since Wan Video separates the 480P and 720P models, we’ll need to provide examples for both resolutions in this guide. In addition to using different models, they also have slight parameter differences.480P Version
1. Workflow and Input Image
Download the image below and drag it into ComfyUI to load the corresponding workflow: We’ll use the following image as input:
We’ll use the following image as input:

2. Model Download
Please download wan2.1_i2v_480p_14B_fp16.safetensors and save it to theComfyUI/models/diffusion_models/ directory.
3. Complete the Workflow Step by Step
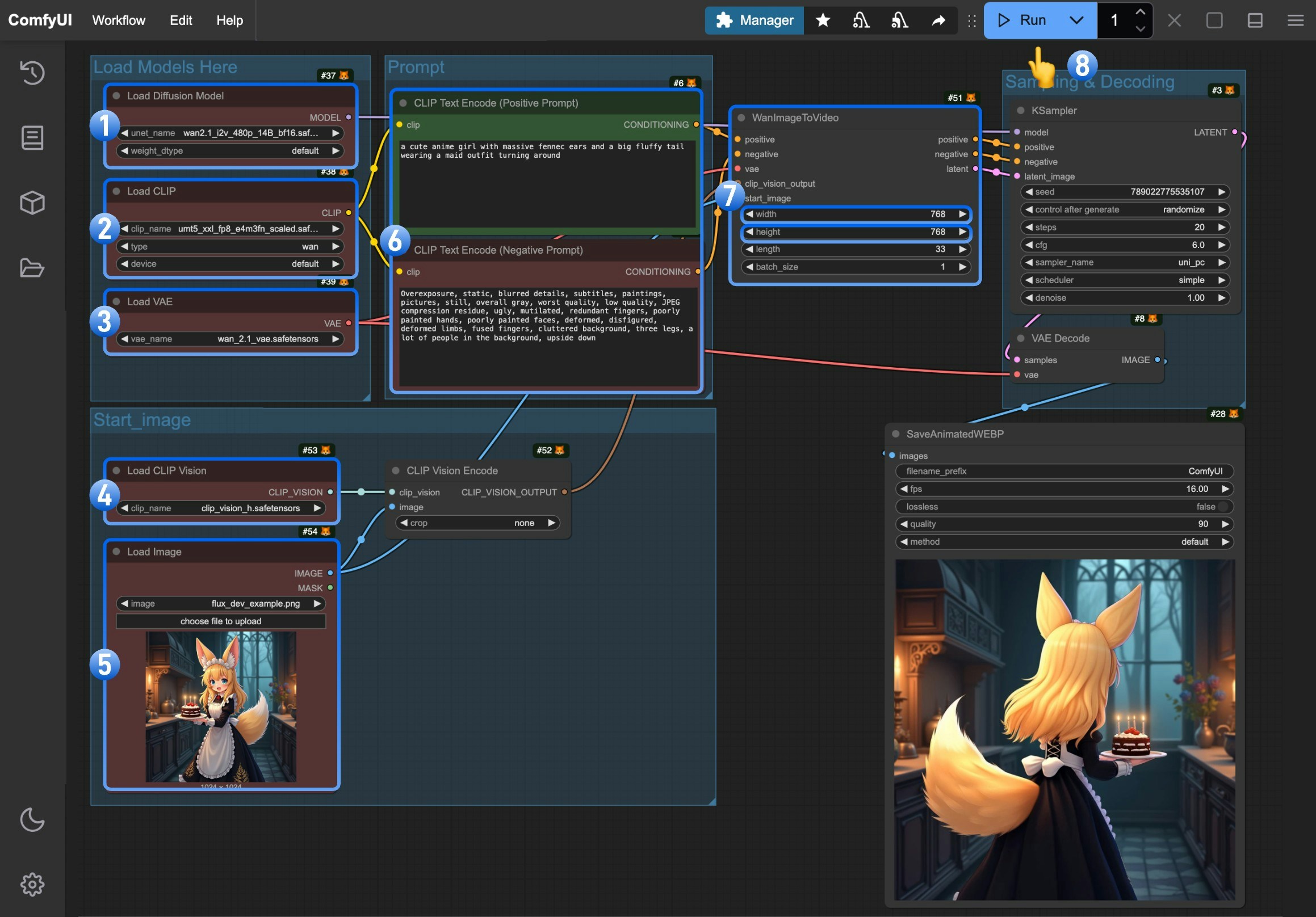
- Make sure the
Load Diffusion Modelnode has loaded thewan2.1_i2v_480p_14B_fp16.safetensorsmodel - Make sure the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Make sure the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - Make sure the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Upload the provided input image in the
Load Imagenode - (Optional) Enter the video description content you want to generate in the
CLIP Text Encodernode - (Optional) You can modify the video dimensions in the
WanImageToVideonode if needed - Click the
Runbutton or use the shortcutCtrl(cmd) + Enterto execute the video generation
720P Version
1. Workflow and Input Image
Download the image below and drag it into ComfyUI to load the corresponding workflow: We’ll use the following image as input:
We’ll use the following image as input:

2. Model Download
Please download wan2.1_i2v_720p_14B_fp16.safetensors and save it to theComfyUI/models/diffusion_models/ directory.
3. Complete the Workflow Step by Step
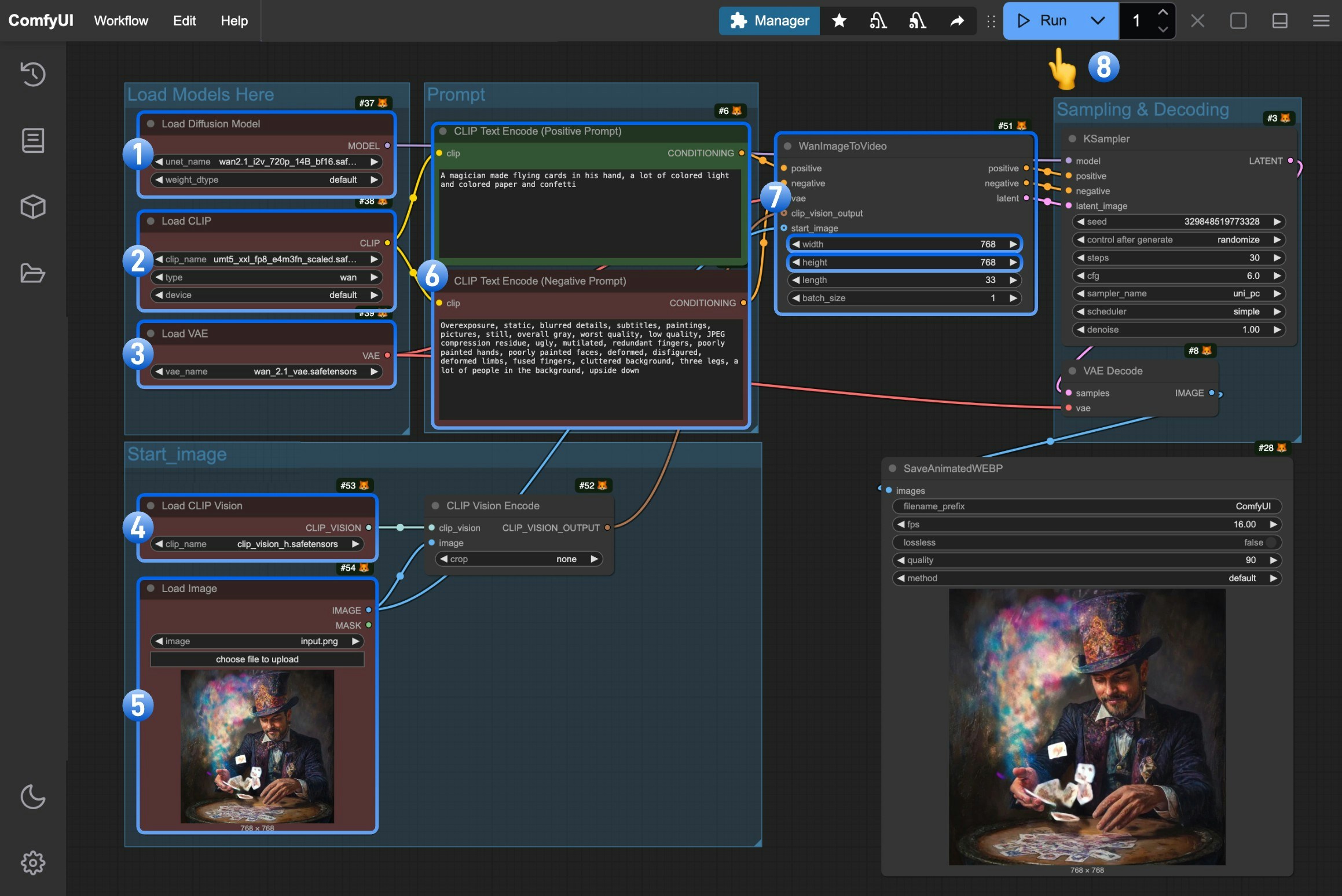
- Make sure the
Load Diffusion Modelnode has loaded thewan2.1_i2v_720p_14B_fp16.safetensorsmodel - Make sure the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Make sure the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - Make sure the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Upload the provided input image in the
Load Imagenode - (Optional) Enter the video description content you want to generate in the
CLIP Text Encodernode - (Optional) You can modify the video dimensions in the
WanImageToVideonode if needed - Click the
Runbutton or use the shortcutCtrl(cmd) + Enterto execute the video generation