Key Features
- Unified Motion Control: Supports trajectory control for multiple motion types including objects, local regions, and camera movements.
- Interactive Trajectory Editor: Visual tool that allows users to freely draw and edit motion trajectories on images.
- Wan2.1 Compatible: Based on the official Wan2.1 implementation, compatible with environments and model structures.
- Rich Visualization Tools: Supports visualization of input trajectories, output videos, and trajectory overlays.
WAN ATI Trajectory Control Workflow Example
1. Workflow Download
Download the video below and drag it into ComfyUI to load the corresponding workflow We will use the following image as input:
2. Model Download
If you haven’t successfully downloaded the model files from the workflow, you can try downloading them manually using the links below Diffusion Model VAE Text encoders Chose one of following model clip_vision File save location3. Complete the workflow execution step by step
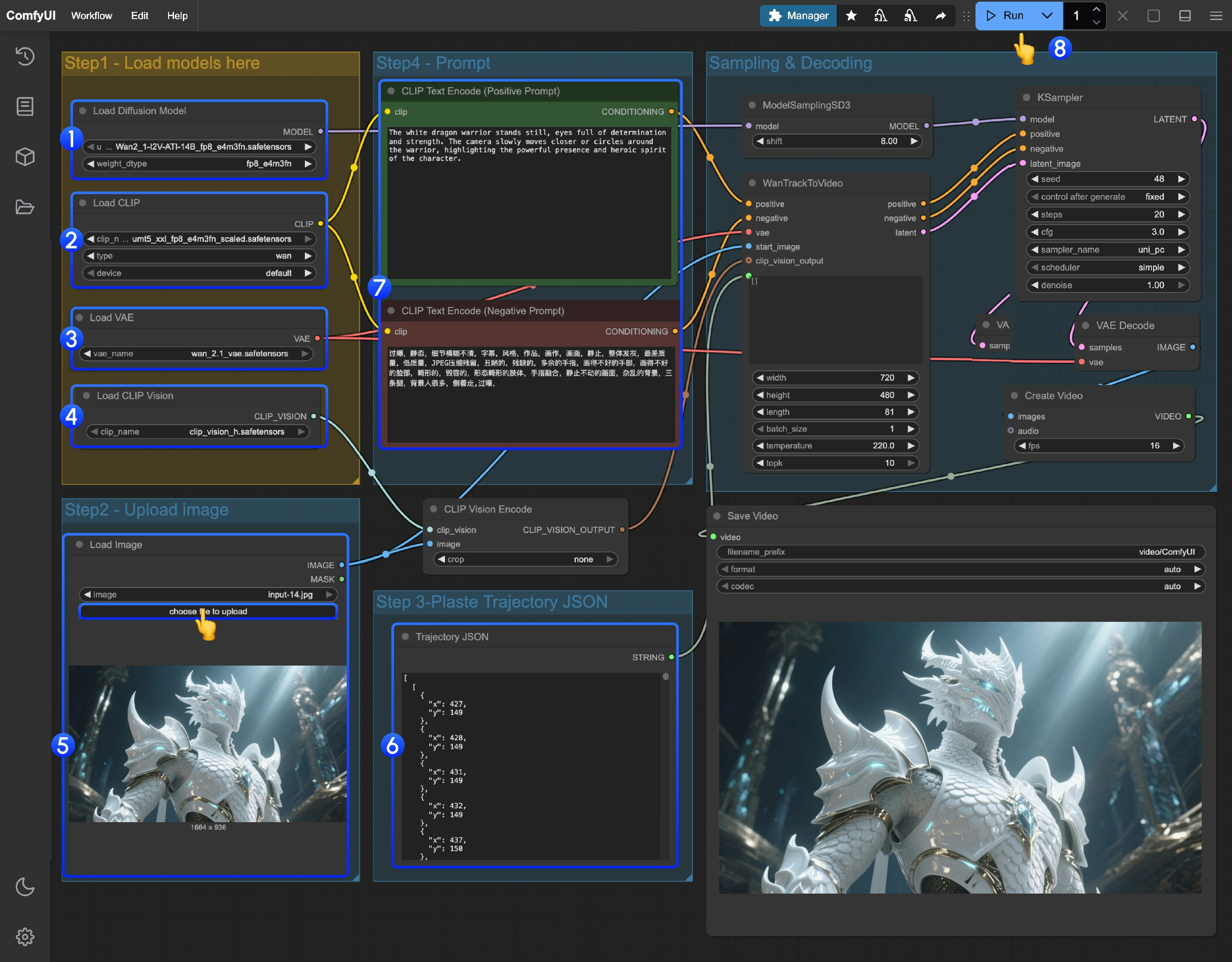
- Ensure the
Load Diffusion Modelnode has loaded theWan2_1-I2V-ATI-14B_fp8_e4m3fn.safetensorsmodel - Ensure the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - Ensure the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Upload the provided input image in the
Load Imagenode - Trajectory editing: Currently there is no corresponding trajectory editor in ComfyUI yet, you can use the following link to complete trajectory editing
- If you need to modify the prompts (positive and negative), please make changes in the
CLIP Text Encodernode numbered5 - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation